Introduction
Table of Contents
In this chapter, we are deep diving into the Docker swarm world. Now, the focus is more on Docker service within Docker Swarm as an integral part of the architecture. Read and practice how to create service, configure rolling updates, configure persistent storage, establish port forwarding and many more. Let’s go…
Docker Engine in swarm mode
Docker engine does not run in swarm mode during initial installation. Swarm mode must be activated explicitly or you can join an existing swarm. Once enabled, services are handled via the Docker service command. Swarm increases service availability and enables cluster mode operation. You can think of Swarm as a transition from individual mode to cluster mode. Let’s see what happens when Docker Swarm init is enabled:
- Node, where swarm mode is activated, becomes part of the swarm cluster named default
- A current node becomes the leading node manager and becomes Active (can receive commands from the scheduler)
- Node manager is actively listening on port 2377
- Node manager runs internal distributed datastores to maintain the consistency of the swarm cluster
- Node manager generates a self-signed CA for the entire swarm and two tokens: manager and worker
- Node manager creates an overlay network called ingress for exposing services to the outside world
- Node manager creates a default IP overlay IP address and a network mask for the network

Docker swarm architecture
Default network address space configuration
If you do not define the address space during Docker swarm initialization, a default one is assigned – 10.0.0.0/8. We can always configure our own subnet space if default one overlaps with our address space or any other reasons. This is done via the default-addr-pool parameter. Additionally, with the default-addr-pool-mask-len parameter, we define the size of the network mask.
Example (Creating a custom subnet network and mask)
We are defining a Docker Swarm with network 192.168.0.0/16 and network mask 25. Notice that we must specify / 16 to know which network class the subnet belongs to.

Configure the advertise address
From the previous example notice that parameter advertise-addr was used with value 192.168.78.3. Manager node advertises itself to other nodes via this address.
Rotation of security token
From the same example above you can see that token was generated for all potential worker swarm members. The procedure is slightly different for potential node managers. It is advisable to rotate tokens every couple of months to protect the entire cluster. The old token will remain valid as long as it is used by existing cluster members.
Example (Token rotation for worker node)
To start token rotation use command docker swarm join-token :

Example 2 (Add worker to swarm)
Add workers (swworker1 and swworker2) in the following way:Notice that token parameter which was generated during swarm initialization was used, and the IP address of the leading manager node.
![]()
Example 3 (Node status)
To monitor node status use the command docker node ls:

Notice the columns STATUS and AVAILABILITY. All nodes are ready and active.
Example 4 (Promotion to manager node)
To promote worker node to manager node use command docker node:
![]()
Degradation to worker node is done with docker node demote:
![]()
Example 5 (Leave the swarm cluster)
To leave swarm cluster use the command docker swarm leave:
![]()
All containers that were running on that node and recreated on first available node to maintain cluster state.
Deploy service to swarm cluster
In the declarative model used by Docker swarm, the defined service state must be maintained. What does that mean? For better insight, let’s look on what states Docker Swarm keeps eye on:
- How many replicas you want to install within the service
- What is the name of the image and version to be used during installation
- Which ports will be exposed to the outside world
- What are the special rules for container placement (resource requirements, placement based on node metadata, etc.)
- Should service start with Docker
Create, update and remove service
During service creation, you can define a number of parameters such as the name of the service, version of the image, command that is executed after the container is started, persistent storage, network, number of replicas and many more.
Example (create update and remove service)
Create service mysql (version 5.7) and start command cat /etc/hostname when container starts:
![]()
Configuration can be changed during service run. For example, to add ports use publish-add parameter:
Mysql service is active and listening on port 3309.
Check configuration:

Delete service by docker service rm:
![]()
Runtime environment, image tags
When running a container, it is possible to define the large number of parameters such as environment variables, working directory, or user under which the container will be run.
Create Ubuntu service with environment variable VAR, working directory /tmp:
![]()
Check the running container and mark its name:
Go inside the container:

Notice that the working directory is /tmp, one defined during container initialization
Environment variable VAR is set to value test as defined:
![]()
Published ports
We are talking about two types of port forwarding (exposing service to outside world): routing mesh and direct route exposure to Docker Swarm node. The difference is that the routing mesh presents the service on each node, regardless of whether the task runs on all of them while direct exposure is tied to a specific node.
Example 1 (service with routing mesh mode)
To create routing mesh define service nginx with two replicas. Internal nginx port is 80 which is mapping to host port 8080:

Notice that Swarm cluster has three members: swmanager, swworker1 and swworker2:

This means that one host is free but still the host listens on port 8080 and forwards traffic to the container on the neighboring host. All hosts participate in load balancing no matter how many replicas are in the cluster.
Services and overlay network
Default network for Docker swarm is overlay network named ingress. Overlay network spans multiple hosts in order to connect running services.
Example (overlay network)
When listing available networks notice overlay network ingress:
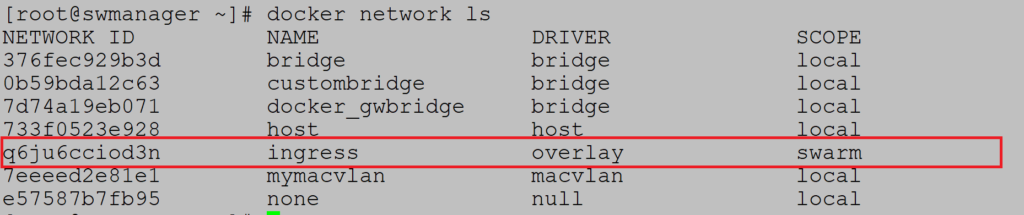
Check that service is connected to ingress network:

You have the freedom to create your own overlay network:![]()
To create service with custom overlay network use network parameter:

Interesting parameters you can use are network-add and network-rm to add network on fly or remove it.
Control service placement
Swarm cluster provides the ability to control scaling and installation of services on specific hosts:
- Setting up service requirements – CPU and memory. Nodes that cannot qualify will not be hosts for such services.
- Do you want to deploy global or replicated services
- Placement constraints. Services will only run on nodes that have specific metadata like datacenter=main.
- Placement preferences. These settings are the last in the chain and have lowest precedence over rules above. For example, let’s label nodes with metadata – web. When you create service with ten replicas, algorithm will try to spread all 10 containers evenly on all nodes with metadata web. But it will also deploy containers on nodes without metadata web but only when all metadata nodes are exhausted.
Example (CPU and memory requirements)
Create service centos with two replicas, with 1GB memory and 1CPU requirement.
Check current node resources:
![]()

Node has 1 CPU and 821 MiB memory.
If you try to create service with 1CPU and 2GB of memory deploy will fail because there is no enough memory:

Drop the requirements to 1CPU and 800MB of memory and service will deploy without issues:

Example 2 (Global and replicated services)
Replicated service create by default. Deploy service with two replicas on the three-node cluster:

Notice that service is deployed on swmanager and swworker2:

Global services need parameter global, no need to define number of replicas because containers are spread on all nodes:

Service is created on all nodes:
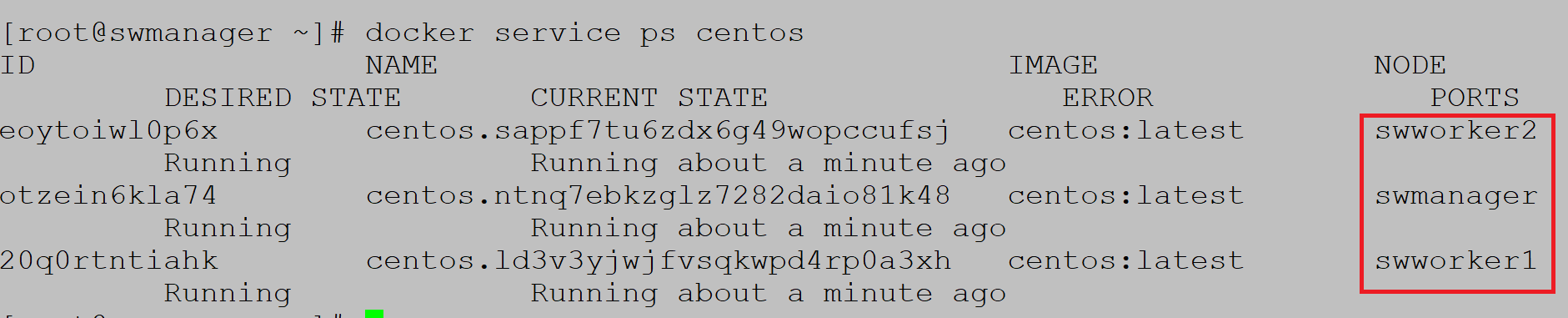
Example 3 (Placement constraints)
You can limit the provisioning of services to nodes with specific metadata defined.
Label node swworker1 with datacenter=main. Use label add parameter:
![]()
Notice that three replicas are created:

But all three replicas are running only on swworker1 as only node with metadata datacenter=main:

Example 4 (Placement preferences)
This method places containers on nodes that have a specific label based on the spread algorithm. This means that the Docker will try to evenly distribute the containers to nodes with a specific label, but will also attempt to allocate them to nodes that do not have that label. Feature is not forced and is of the lowest priority which means that all previous features are executed first.
Label swworker2 and swmanager with datacenter label:

Create service with two replicas and parameter placement-pref for Docker to spread containers evenly on metadata nodes:

Notice that containers are running on metadata nodes swworker2 and swmanager:

Create service with replicas to check where third container will be placed:

Third container is running on swworker1, the node that has no metadata defined:

Configure a service’s update behavior
There are many options when upgrading a service with a new version of image. By default, the update is done on a single container and if at any step goes wrong, the whole procedure fails. You can also define delay between containers upgrade via upgrade parameter. Upgrading the second container starts only if the first container is successfully upgraded and in running status.
Create alpine service with three replicas:

Update the service with the latest version. Update delay is set to 10s, two containers in parallel and update continue if process fails in any stage of update:

Check that alpine runs on latest version:

If you want to downgrade version use rollback parameter:

Check that version is 3.4 again:

Finally, you can create a service that automatically reverts to an older version of the image if the upgrade fails. Create a service Centos with three replicas, two rollbacks in parallel, container monitoring for 20s in case the container shutdown, and 30% tolerance error:

Volumes and binds
For services, you can define some form of permanent data storage. In the article Docker storage you can see that there are two main types of permanent data storage: volume and bind mount. The main difference is that the volume has a separate file system on the host that is controlled via the Docker CLI, while the bind mount filesystem can be located anywhere on host and not manageable through the Docker CLI.
Data volume
Data volume is a type of permanent data storage and is an independent entity which means that it can be pre-created and must be deleted separately.
Example (Create service with data volume)
Create service Centos with data volume centvolume which maps to container path /tmp:

Bind mounts
Bind mounts unlike volume data can have filesystem anywhere on the host which makes less flexible solution for permanent storage:
- You must provide the dedicated filesystem on the host
- Filesystem must be available on all nodes in the swarm cluster in case of container recreation on another node
- Not portable
- Cannot be managed via Docker CLI
Example (Service creation with bind volume)
Same as data volume with additional parameter type=bind:
